附件为19页PDF文件。
过去几年,企业谈大模型落地,最容易被放大的议题往往是算力、模型和知识库。好像只要底座更强、参数更大、推理更快,智能能力自然就会在企业里生长出来。但真正进入业务现场之后,问题很快变得具体而尖锐:模型可以很聪明,却未必听得懂企业的业务语言;系统里明明有大量数据,却未必找得到、取得出、解释得清;AI 可以生成一段看上去完整的分析结论,却很难证明口径是否正确、来源是否可靠、过程是否可追溯。
这正说明,企业从大数据走向大模型,最先暴露出来的短板,往往不是算力不足,而是数据与业务之间长期缺少一层稳定的翻译机制。企业真正缺的,不是更多数据,也不只是更强模型,而是一套能够把业务语义、数据结构、执行逻辑和治理规则连接起来的中间层。这个中间层,就是数据语义层。
一、大模型进入企业,先遇到的不是“会不会回答”,而是“能不能读懂数据”
传统大数据体系的核心目标,是把数据集中起来、加工出来、展示出去。围绕数据仓库、数据湖、指标平台、BI 看板和标签系统,企业已经积累了相当成熟的方法体系。这套体系可以较好地支撑“人来用数据”的场景,因为人能够通过经验、沟通和上下文理解去弥补系统的不足。指标口径有争议,可以开会对齐;字段含义不明确,可以找熟悉系统的人确认;权限链路复杂,也可以靠审批和协调勉强打通。
但当数据消费者从分析师扩展为数据智能体,问题的性质就变了。智能体不是不能生成答案,而是很容易在理解环节失真。业务人员口中的“高价值用户”“有效订单”“净收入”“客户流失”,在企业内部未必天然统一;同一个概念在不同系统中,可能对应不同表、不同字段、不同时间口径;即便找到了数据,也可能因为权限、性能、ETL 排期和链路复杂而无法及时完成分析。对人来说,这些问题是低效;对 AI 来说,这些问题会直接导致失真。
所以,AI 时代的数据问题,已经不只是“能不能算”,而是“能不能被机器正确理解并可信使用”。这就是为什么很多企业大模型试点看起来热闹,真正进入经营分析场景时却迟迟落不下去。问题往往不在模型,而在模型读不懂企业数据。
二、企业 AI 用不好数据,通常卡在三件事:找不到、取不出、说不清
企业数据智能体的第一道障碍,是找不到数据。所谓找不到,不只是字面上的检索困难,而是更深层的语义缺失:不知道企业里有哪些数据,不知道哪个字段对应哪个业务概念,不知道相似表之间的差异,也不知道同名指标背后的计算口径是否一致。没有统一语义,数据越多,迷雾反而越大。
第二道障碍,是取不出数据。企业分析不是在真空中完成的,它受制于权限、安全、性能、资源和工程机制。很多时候,即便知道需要什么数据,也可能因为访问受限、查询过重、宽表不适配或者 ETL 排期过长而迟迟拿不到结果。人还能通过流程和协调去兜底,智能体却无法依赖这种临场协作。
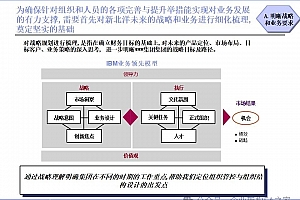
第三道障碍,是说不清结果。企业真正不信任 AI 的地方,通常不在于它不会写结论,而在于它说不清“为什么是这个答案”。一个分析结果如果无法说明指标定义、数据来源、所用表字段、转换逻辑以及受哪些权限规则约束,那么它即使看上去合理,也很难进入经营决策。文中将这种可信性概括为“三真”——口径真、数据真、血缘真;将可用性概括为“三好”——听力好、眼力好、脑力好。表达或许偏传播化,但它点出了企业场景里最关键的判断:AI 首先不是要“会说”,而是要“说得真、说得准、说得清”。
三、数据语义层补的,不是一个 BI 功能,而是业务与数据之间的翻译层
很多人一提语义层,第一反应还是 BI 工具里的语义模型,或者指标平台中的业务对象抽象。这种理解不能说错,但已经不够了。在大模型时代,数据语义层的价值不再只是让报表更好做,而是要为所有分析与 AI 工作负载提供统一的业务语义。它不是一个显示层的小能力,而是企业数据架构中的关键中间层。
它至少承担三项职责。
第一,把业务语言翻译成数据语言。业务术语、指标定义、分析维度和实体关系,必须被结构化表达,形成可复用、可共享、可解释的统一语义。只有当“同名同义”成为基础能力,AI 才可能真正理解企业的问题。
第二,把语义定义翻译成可执行的查询和动作。语义层不能停留在术语词典层面,而必须能够把语义规则编译成 SQL、查询计划和数据调用逻辑,并与现有仓库、湖仓、指标平台和权限体系联动起来。离开执行能力,语义层只是知识描述;具备执行能力,语义层才会变成生产系统。文中也明确把语义层的关键能力概括为语义定义、语义执行和语义管理三类,其中执行能力还涉及语义编译、查询优化、ETL 编排以及跨库跨源连接。
第三,为结果建立可信链路。语义层真正重要的,不只是帮助 AI 找到数据,更是帮助企业证明答案为什么成立。指标来自哪里、口径如何定义、依赖了哪些表、经过了哪些转换、受到哪些权限约束,最终都应当能沿着血缘链条追溯出来。只有这样,AI 的分析结果才可能从“看起来不错”走向“可以被采信”。
四、数据架构的下一步,不只是做强底座,而是补上语义中枢
从架构视角看,数据语义层真正重要的地方,在于它改变了企业数据体系的重心。过去,企业更关注从数据源到仓库、从仓库到应用的加工链路,核心是存储、计算、建模和交付。而在 AI 时代,这条链路之上必须再建立一层稳定的语义结构,把业务实体、指标、维度、标签、权限、血缘和上下文组织起来,形成机器可理解、可调用、可验证的业务语义。文中将这种转变概括为从“Data Warehouse”走向“Semantic Fabric”,虽然带有一定厂商话语色彩,但其背后的趋势判断是成立的:企业竞争的焦点,正在从“谁拥有更多数据”,转向“谁更能把数据组织成 AI 可用的语义资产”。
当然,语义层并不替代数据仓库,也不绕开主数据、指标治理、元数据、血缘、安全与组织协同这些基础工作。恰恰相反,它是把这些原本分散的治理成果组织成统一机器接口的一层能力。没有底层明细数据和治理规则,语义层会沦为空壳;但只有底层平台、没有语义层,AI 又始终难以真正进入企业经营。
因此,从大数据到大模型,企业真正缺的不是算力,而是数据语义层。算力解决的是模型跑得快不快,语义层解决的是模型懂不懂企业、用不用得对、结果能不能被信任。没有语义层,AI 最多只是一个会说话的界面;有了语义层,AI 才可能成为真正可用的数据使用者。谁先补上这层能力,谁才更有可能把沉淀多年的数据资产,真正转化为可被 AI 消费、可进入决策闭环的 AI 资产。
五、19页PDF



EA之家 » 从大数据到大模型,企业真正缺的不是算力,而是数据语义层,附研究案例